MARS8: The Multilingual Text-to-Speech Model Built for Production
MARS8 is a family of production-grade text-to-speech models built so every use case, language, and voice profile gets the same rock-solid reliability when millions are listening.











Live-Ready Voice vs Everything Else

.avif)

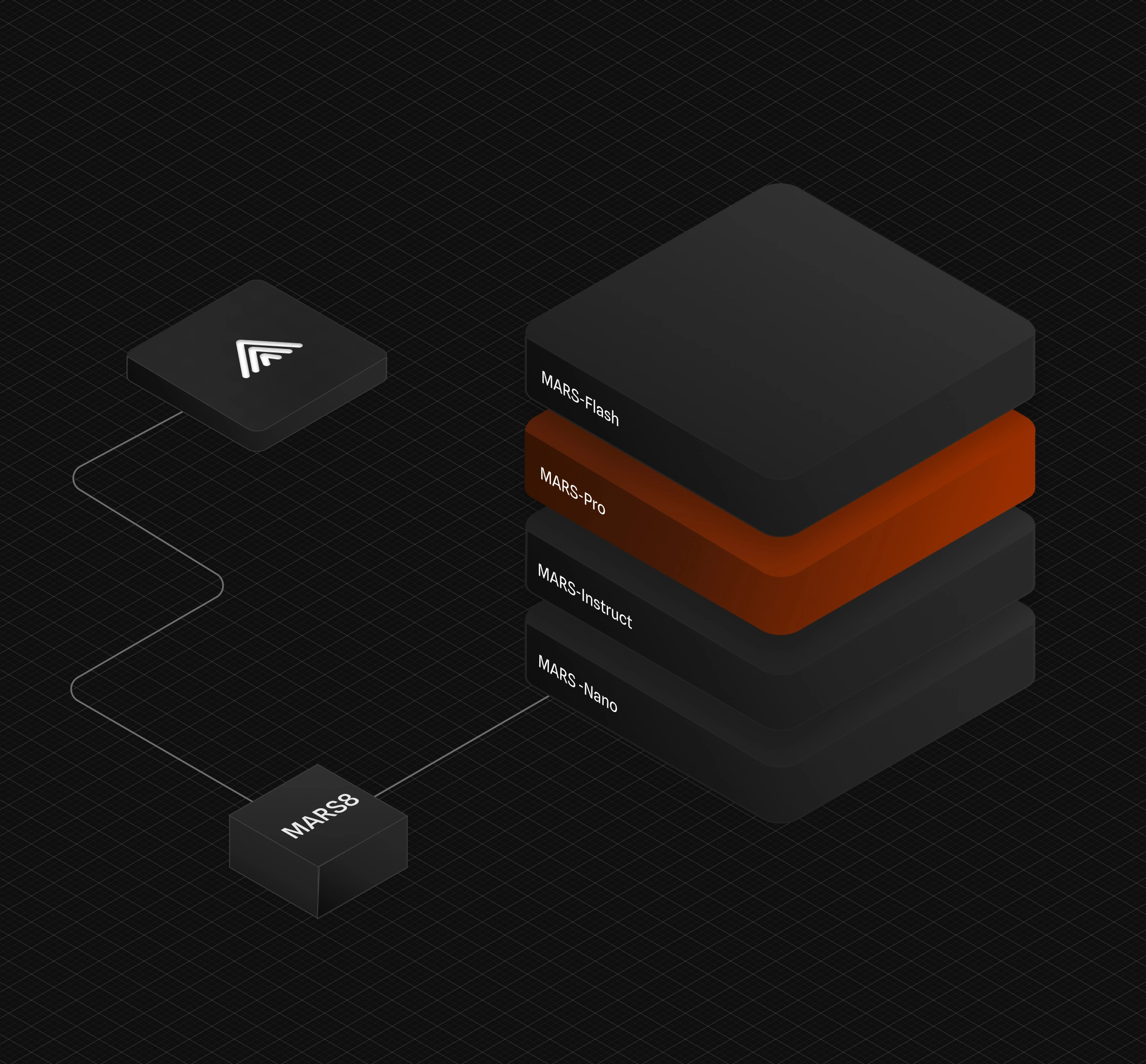
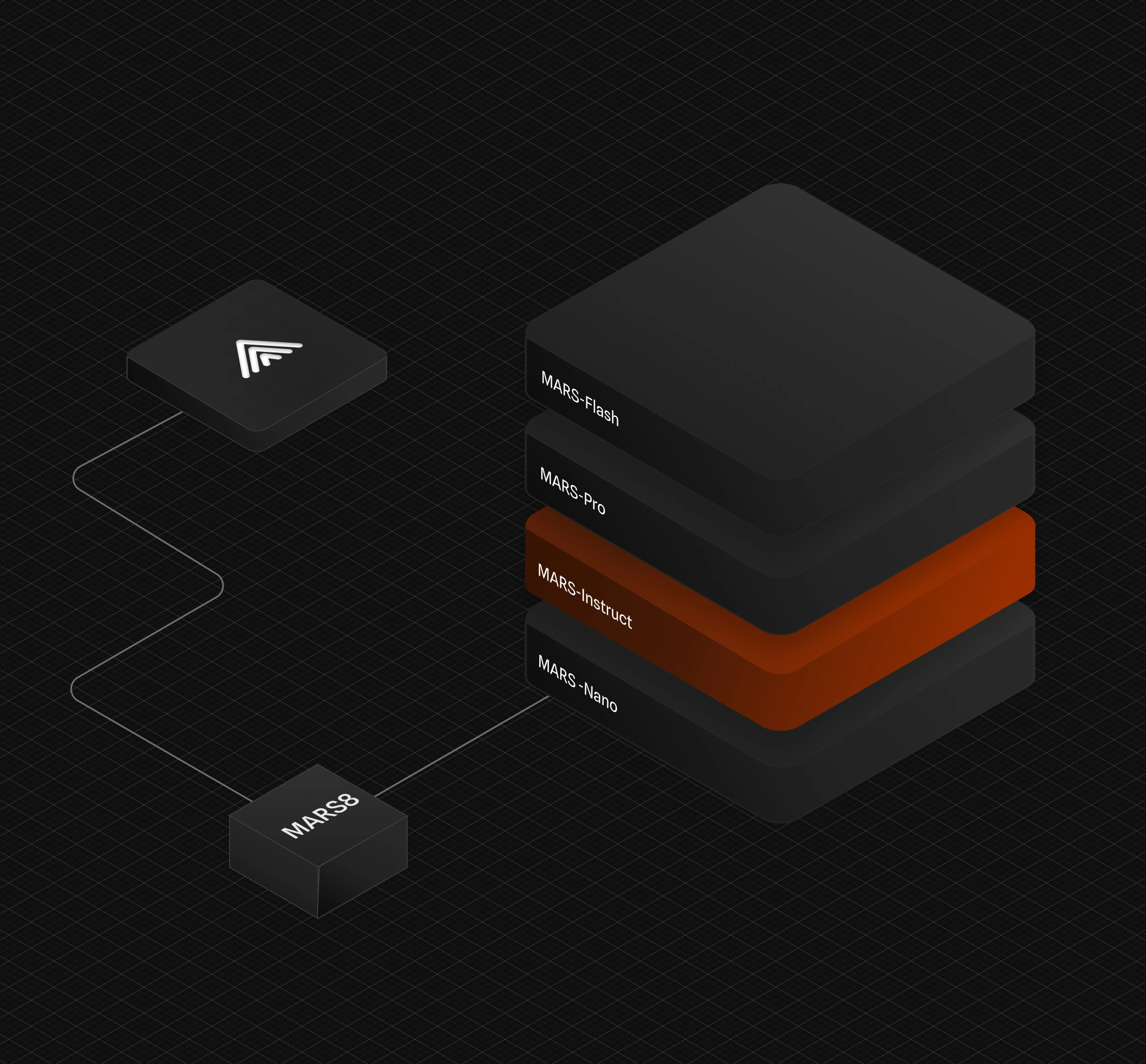
The MARS8 family
Specialized models for each use-case
Read our full research blog post →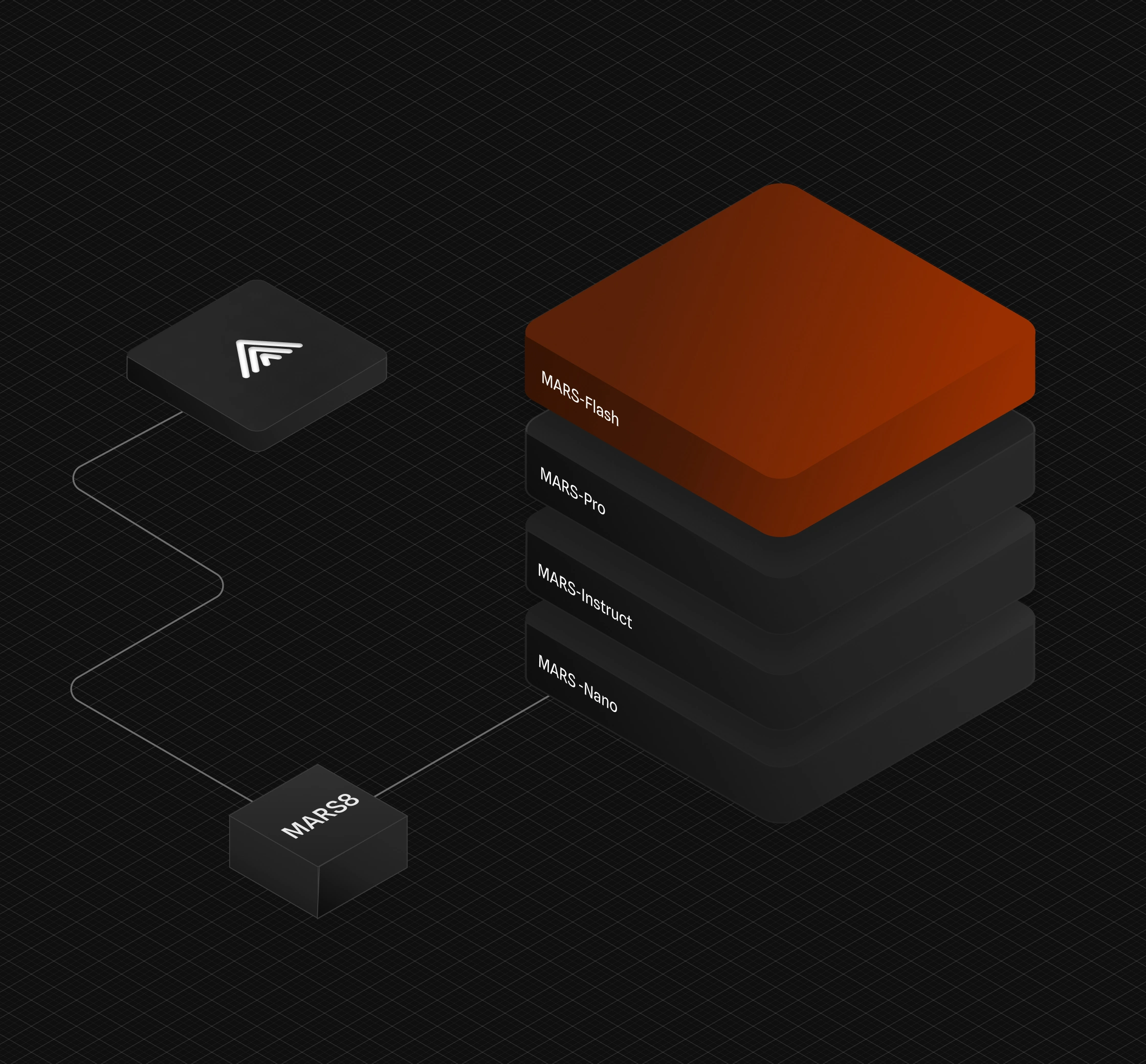
Contact centers
Live conversational AI
Audiobooks
Digital media
Precise prosody control
Creative editing workflows
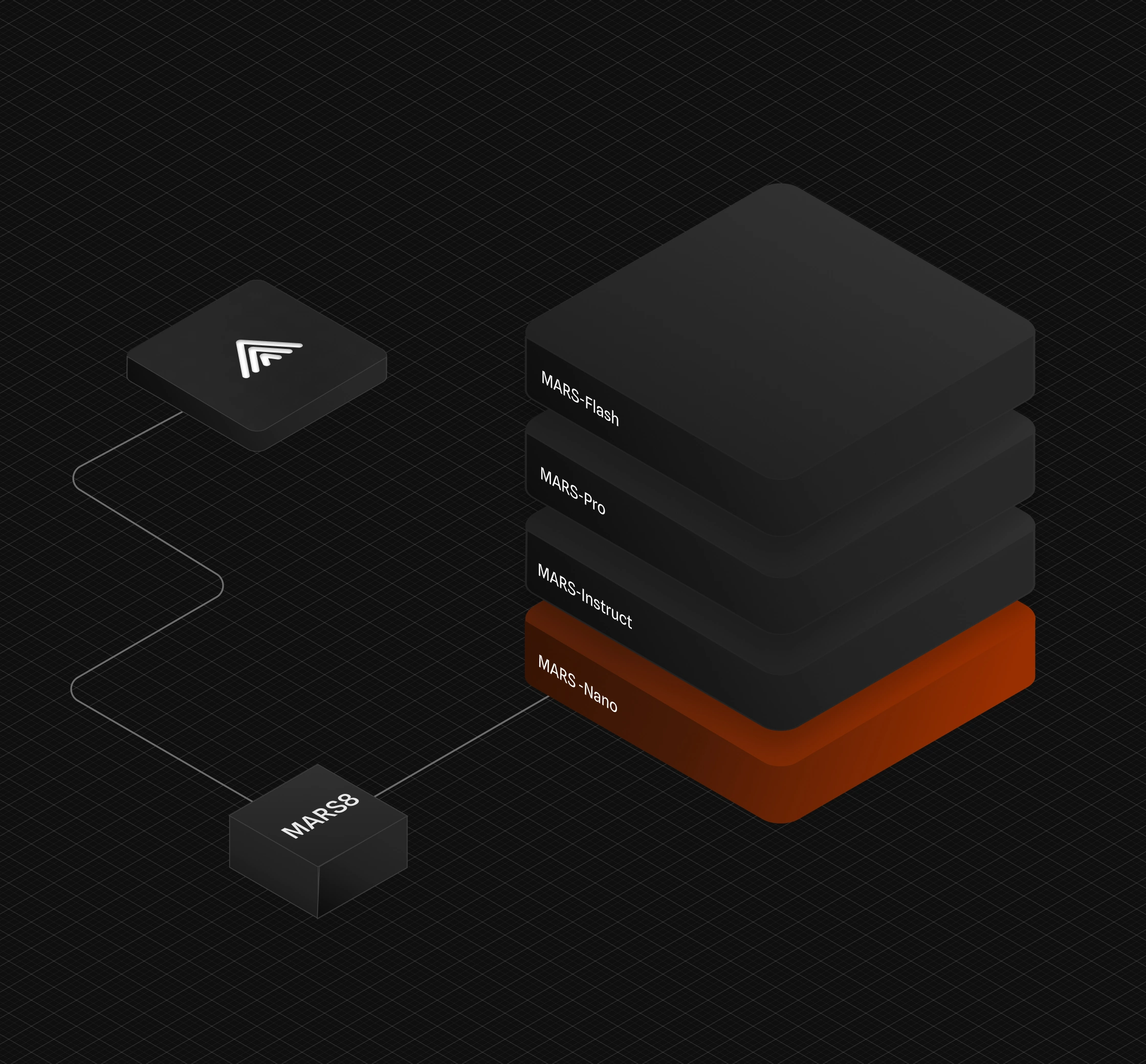
Embedded devices
Edge deployments
Approximate mean opinion score on a 1–10 scale, predicted by Meta’s Audiobox‑Aesthetics model; higher PQ indicates better production quality.
Speaker similarity metric measured as the mean cosine similarity between generated audio and reference audio, using the wavlm-base-sv embedding model.
Speaker similarity metric measured as the mean cosine similarity between generated audio and reference audio, using the CAM++ embedding model.
Approximate mean opinion score on a 1–10 scale, predicted by Meta’s Audiobox‑Aesthetics model; higher CE reflects greater content enjoyment.
Percentage of characters that are incorrect in the generated output, as measured by Whisper ASR.




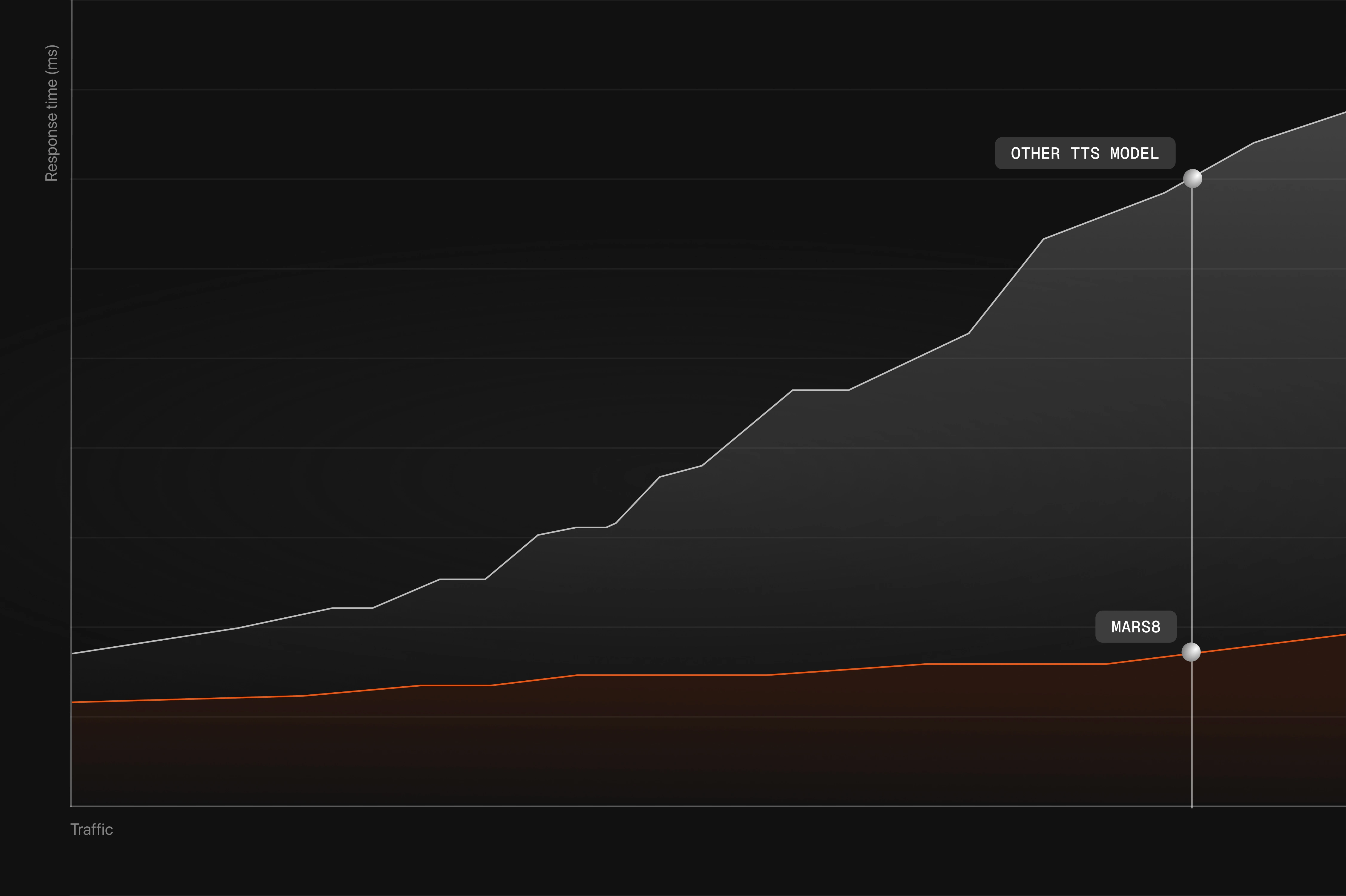
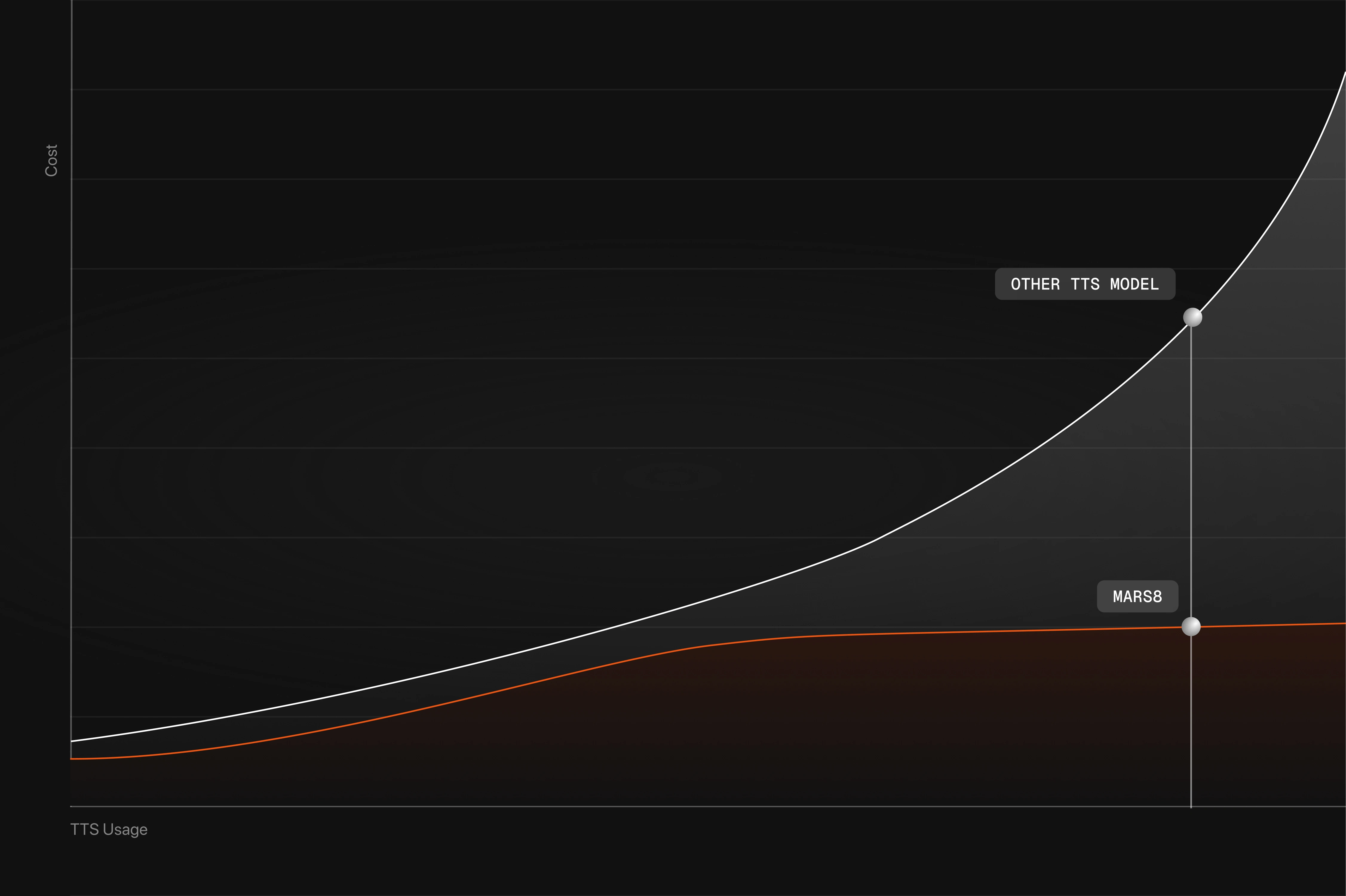
Voice AI that moves you from demo‑ware to production realities.
Voice systems behave very differently at scale. Once latency budgets tighten, usage spikes, and compliance kicks in, architectural decisions start to dominate outcomes. MARS8 is built for these real‑world constraints, not for API convenience.
Global language coverage

.svg)
.svg)
.svg)
.svg)

.svg)
.svg)
.avif)
.svg)
.svg)
.avif)
.svg)
.svg)
.svg)
.svg)
.svg)
.png)
.avif)
.avif)
.svg)
.png)
.png)
.svg)
Want the full technical breakdown?
For a detailed look at MARS8’s architecture, deployment patterns, and performance characteristics, read the full technical article on our blog.
on your terms
Whether you’re building a product or enabling others to build, there’s a direct path to get started.




