MARS8 Model Family: Technical Specifications and Benchmark Results

Introduction
Today, we introduce MARS8, our first full family of text-to-speech (TTS) models.
Through real-world deployments across entertainment, sports broadcasting, and AI agents, we learned a fundamental lesson: no single TTS model can excel at every use case. Different domains demand different trade-offs between expressiveness, latency, controllability, and robustness.
Our journey began with MARS5, the first TTS system capable of handling high-intensity prosody at the level required for live sports commentary. MARS5 was open-sourced in English and quickly trended to #3 on Hugging Face, ranking just below models such as Gemini and Llama. We then expanded with MARS6 and MARS7, which became the first TTS models to be inducted into AWS Bedrock and Google Model Garden respectively.
In this document, we present the capabilities of MARS8, outline the different models within the family, and share detailed technical and academic benchmark evaluations. We evaluated MARS8-Pro and MARS8-Flash (two models from the TTS family) head-to-head against leading TTS systems in the industry, including Cartesia Sonic-3, ElevenLabs Multilingual v2/v3, and Minimax Speech-2.6-HD.
All evaluations and datasets are fully open-source, ensuring that our benchmarks are transparent and replicable by the broader research and developer community.
The results demonstrate that MARS8-Pro and MARS8-Flash achieves state-of-the-art performance in speech quality and speaker similarity, while excelling in challenging real-world scenarios. Most recent TTS models have been driven by an industry-driven heavy optimization for narrow, agent-centric use cases. The MARS8 TTS family breaks through this ceiling while maintaining excellent quality for agentic use-cases.
In this report, we focus on MARS-Pro, our most versatile model balancing expressive performance, and MARS-Flash, optimized for agentic use cases and low-latency synthesis. In a follow-up blog, we will present benchmark results for MARS-Nano and MARS-Instruct.
What Makes MARS8 Different
Most TTS benchmarks evaluate models under ideal conditions: long, clean reference audio recorded in studio environments. But real-world applications rarely have this luxury. Users provide short clips, often recorded on phones, with background noise and natural expressiveness. Dubbing requires to replicate changing emotions across voice identities and in a lot of cases changing emotions within personas.
We designed MARS8 to excel precisely where other models struggle. The defining capability is exceptional performance from limited data and information. Even with audio as brief as 2 seconds, MARS8 maintains a highly consistent speaker identity and performance - something that typically requires 10-30 seconds of clean audio with competing systems.
MAMBA: The “Kobe Bryant” of TTS benchmarks.
To validate these claims, we developed the MAMBA Benchmark, a rigorous stress test designed to reflect the most demanding real-world conditions, rather than idealized studio environments.
The name MAMBA is intentional. Our team at CAMB deeply resonates with the mamba mentality: a relentless commitment to excellence, discipline, and continuous improvement. Kobe Bryant’s legacy stands as a powerful testament to what sustained hard work and focus can achieve, even when starting as an underdog. In the same spirit, the MAMBA Benchmark embodies difficulty by design, prioritizing the hardest cases, not the easiest ones.
Today, we are open-sourcing the MAMBA Benchmark so the broader community can independently replicate and validate our results. Our goal is for MAMBA to serve not only as a transparent validation framework for our own models, but also as a durable, industry-grade benchmark against which future TTS systems can be evaluated.
Benchmark Design

Three key design decisions make the MAMBA benchmark dataset particularly challenging:
1. Cross-language voice cloning
70% of samples require cloning a voice across different languages. This tests both pronunciation robustness and identity preservation. If a model can maintain speaker similarity while switching from, let’s say, English to Mandarin, it demonstrates that the robustness extends to many harder practical use cases where voices must be cloned cross-lingually.
2. Ultra-short references
The average reference duration is just 2.3 seconds, with the most common samples being only 2 seconds long. This mirrors real-world constraints where users rarely have access to lengthy, clean recordings. This is true across agentic, video-on-demand or live scenarios.
3. Expressive source audio
References contain natural expressiveness rather than neutral read speech. Real voices have emotion, emphasis, and variation. Models need to capture identity without being thrown off by expressive delivery.
Results
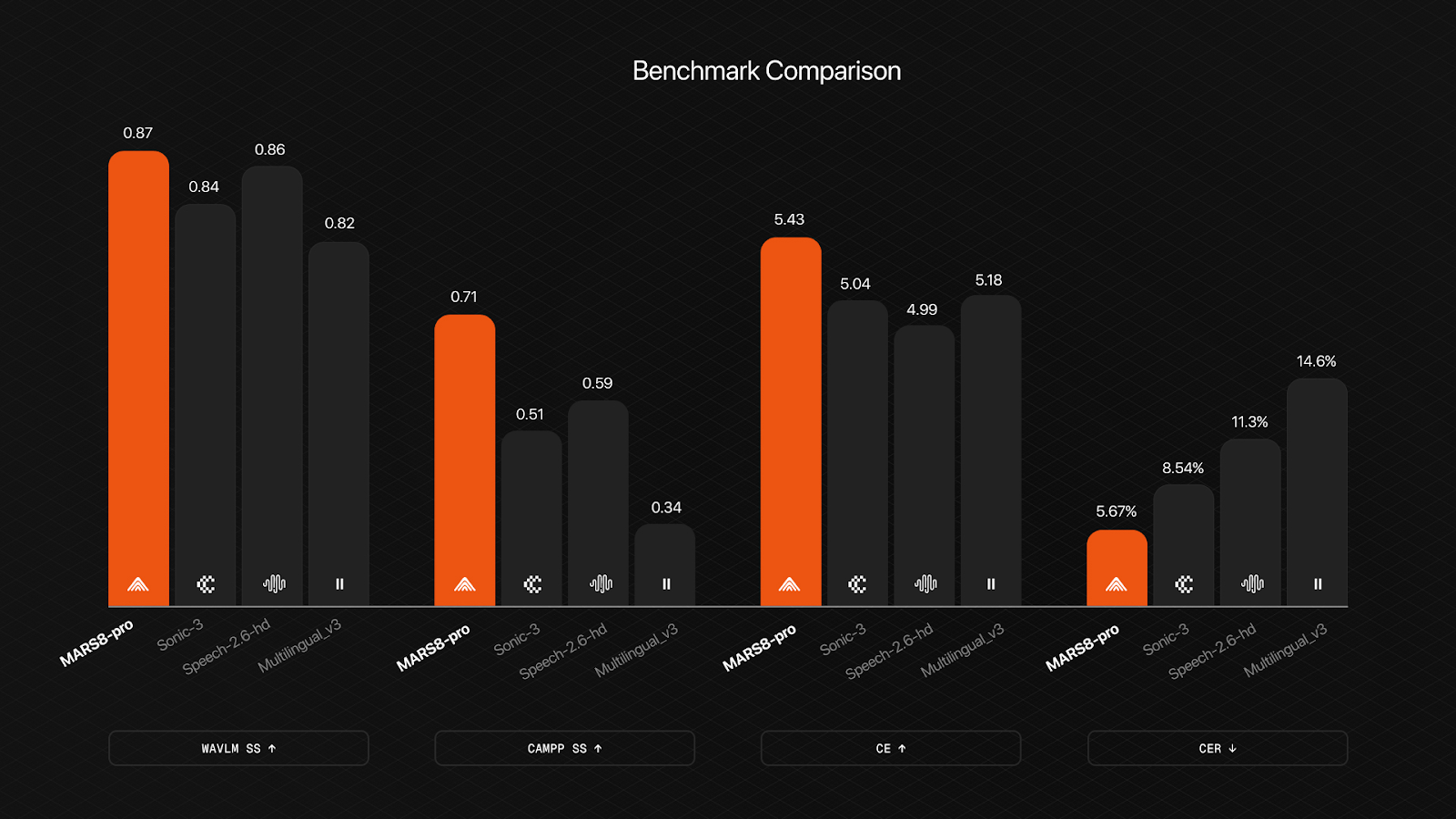
We benchmarked the MARS8 family against top competitors: Elevenlabs Multilingual V2 (referred to in the results tables as Multilingual v2), Elevenlabs Multilingual V3 (referred to as Multilingual V3), Minimax Speech 2.6 HD (referred to as Speech-2-6-HD), and Cartesia Sonic 3 (referred to as Sonic-3)
Speech Quality
We measured speech quality using two metrics: Content Enjoyment (CE) and Production Quality (PQ), both scored via Facebook’s audio-aesthetics model on a scale of 1-10.
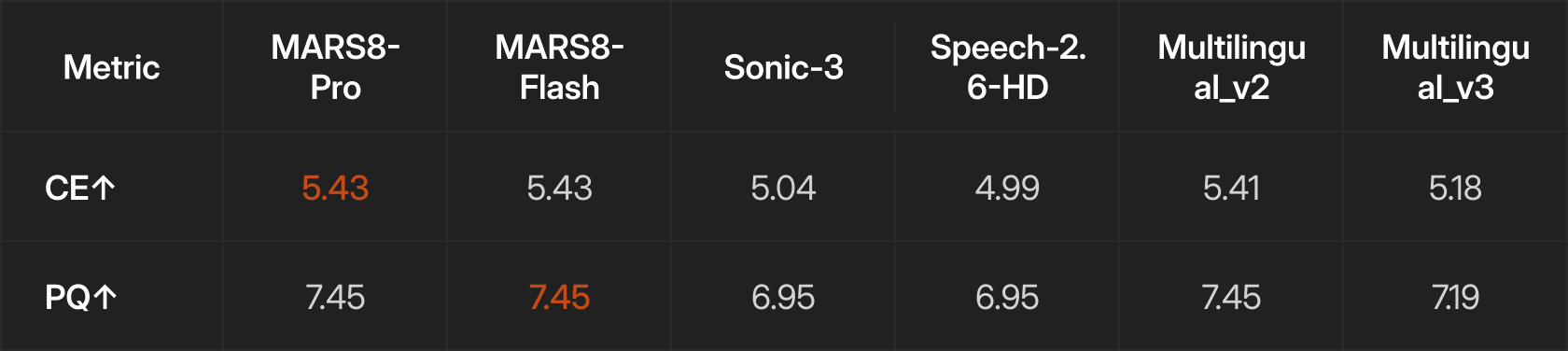
MARS8 leads on CE while matching the best performers on PQ, indicating that our model produces speech that sounds both natural and professionally produced.
Character Error Rate
Character Error Rate (CER) measures transcription accuracy via whisper-large-v2 — lower is better.

MARS8-Flash achieves 5.67% CER, demonstrating strong pronunciation accuracy across the multilingual test set. While ElevenLabs Multilingual v2 edges ahead on this metric, it significantly underperforms on speaker similarity (see below) — suggesting it may sacrifice voice fidelity for pronunciation clarity.
Speaker Similarity
This is where MARS8 truly shines. We measured the speaker similarity using the mean cosine similarity between speaker embeddings as produced by two high performing speaker verification modals – wavlm-base-sv (WavLM), and CAM++.
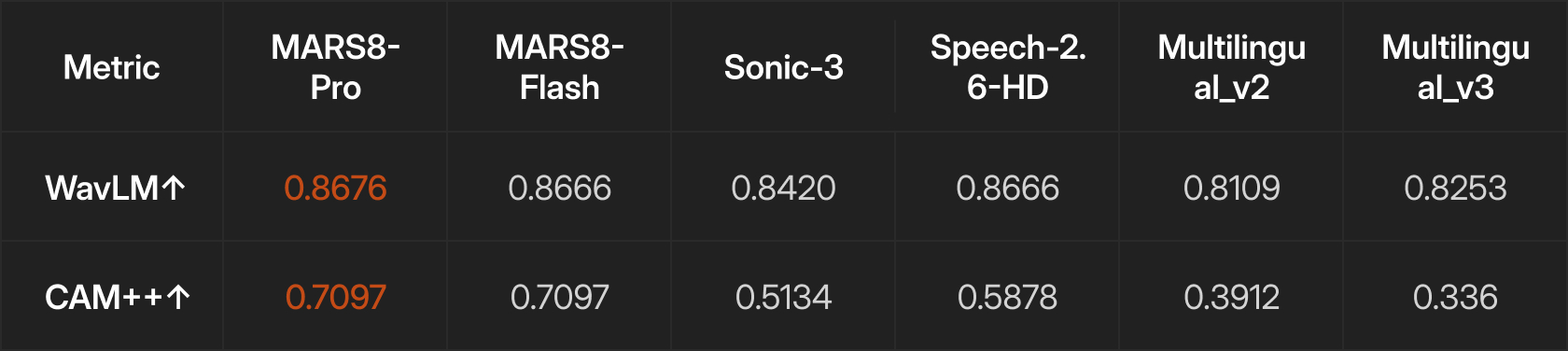
MARS8-Pro achieves the highest scores on both metrics: 0.87 on wavlm-base-sv cosine similarity and 0.71 on CAM++.
The performance with CAM++ embeddings is particularly striking. MARS8’s similarity score of 0.71 represents a 38% improvement over the next best competitor (Speech-2.6-HD at 0.59) and more than double the score of ElevenLabs Multilingual v2 (0.39).
This gap widens further when you consider that these results were achieved with an average reference length of just 2.3 seconds. MARS8 maintains speaker identity from minimal audio in ways that other models simply cannot match.
Key Takeaways
MARS8 demonstrates consistent superiority across the dimensions that matter most for production deployments:
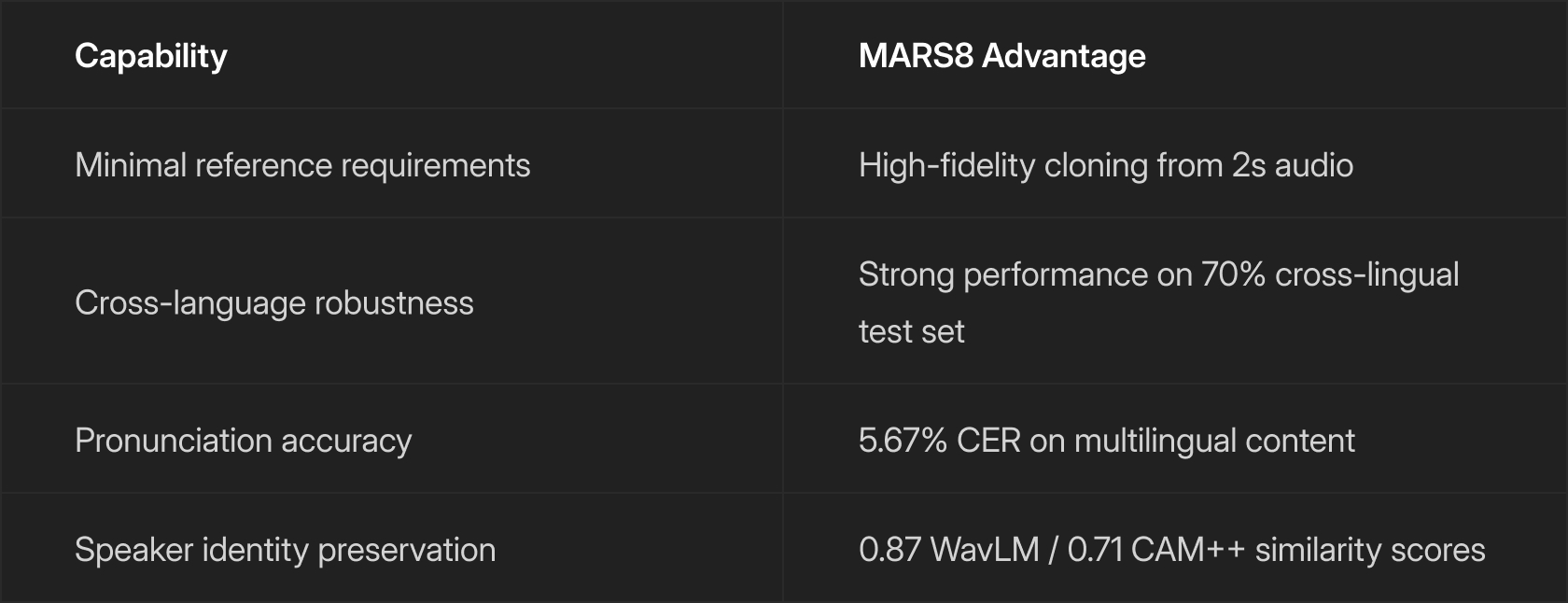
The bottom line: if your application requires voice cloning from short, real-world audio samples, MARS8 delivers the best available combination of quality, accuracy, and speaker fidelity.
Methodology
All evaluations follow standardized protocols to ensure reproducibility:

The evaluation data, cleaning pipeline, and metric definitions are fully open-sourced in our Mamba TTS Benchmark repository.
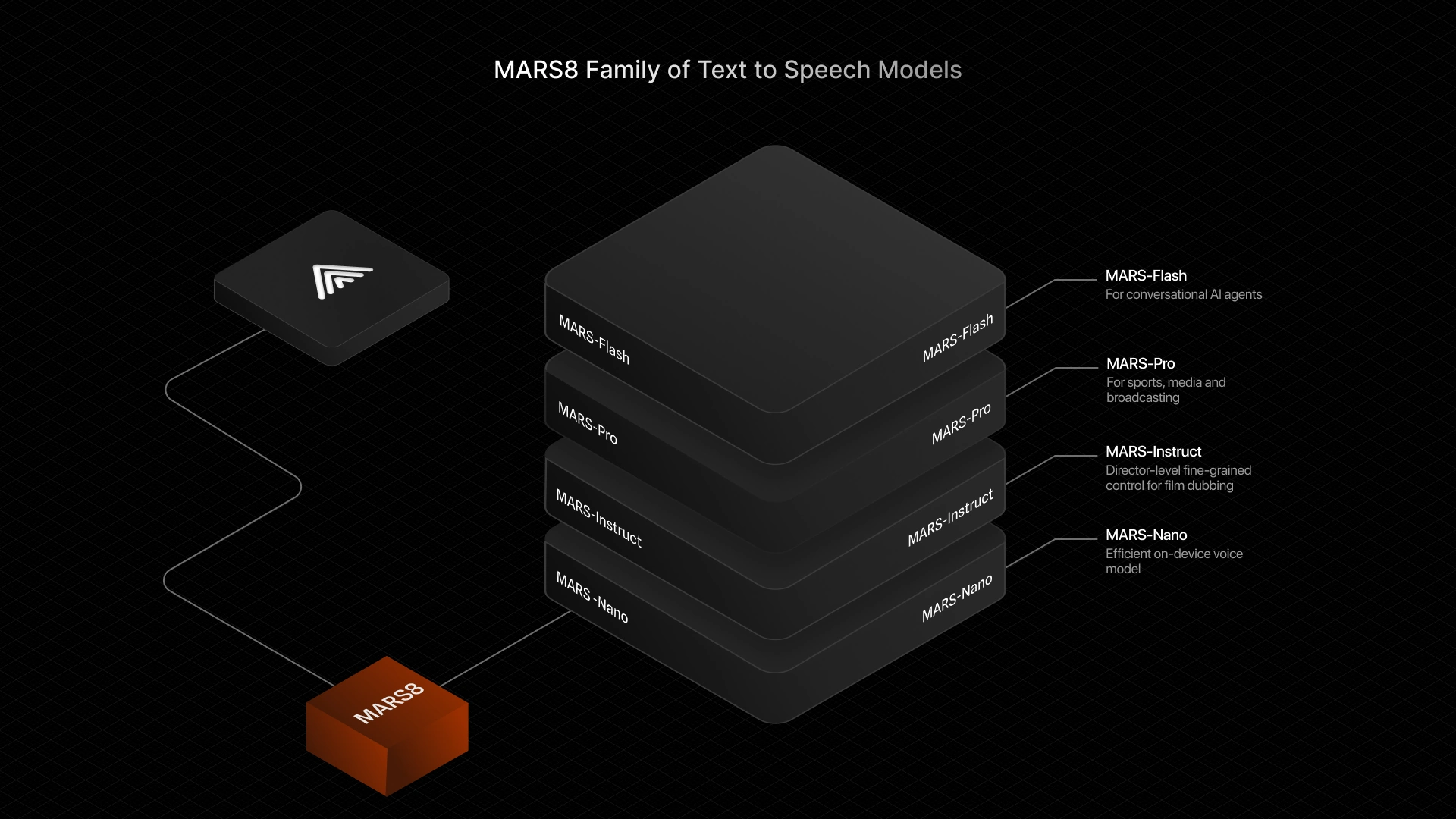
The MARS8 Family
All models in the family are zero-shot TTS models with multi-lingual support. Model types vary i.t.o. speed, quality, controllability and use-case fitment.
- MARS-Flash: Ultra-low latency for real-time agents and assistants.
- Parameters: 600M
- TTFB: As low as 100ms, depending on GPU. Best speeds available on Blackwell GPUs like the Blackwell RTX PRO 6000. Other good GPU model types are L40S.
- Use case: agentic conversations, e.g., call center agents, live conversation agents.
- MARS-Pro: The balance of speed and fidelity for real-time translation with voice and emotion transfer.
- Parameters: 600M
- TTFB: 800ms - 2s, depending on GPU and payload.
- Use case: expressive dubbing content, audiobooks and digital media when short or hard references are provided. General best performance if speed is not a concern.
- MARS-Instruct: Director-level emotion controls for high-end TV and film production.
- Parameters: 1.2B
- TTFB: Higher, not meant for real-time applications.
- Use case: specific style needs, where the speaker and prosody can be independently tuned using a reference and a textual description of desired prosody. E.g., in movie dubbing editing, where precise control is desired.
- MARS-Nano: Highly efficient architecture for on-device applications.
- Parameters: 50M
- TTFB: As low as 50ms (depending on the type of on-device compute)
- Use case: on-device applications where memory and compute are substantially constrained. Currently deployed on partners and providers like Broadcom. Also works great for agentic use-cases.
Language support
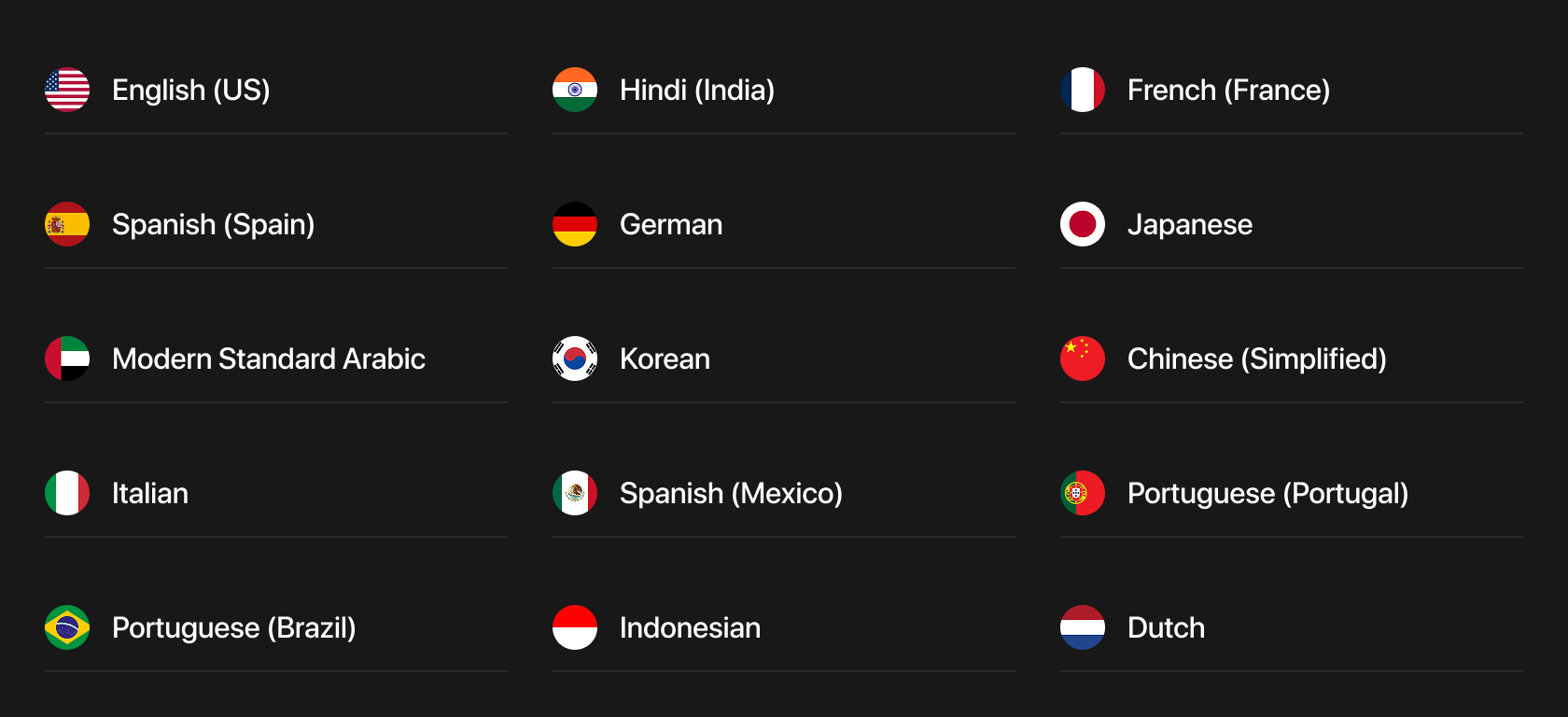
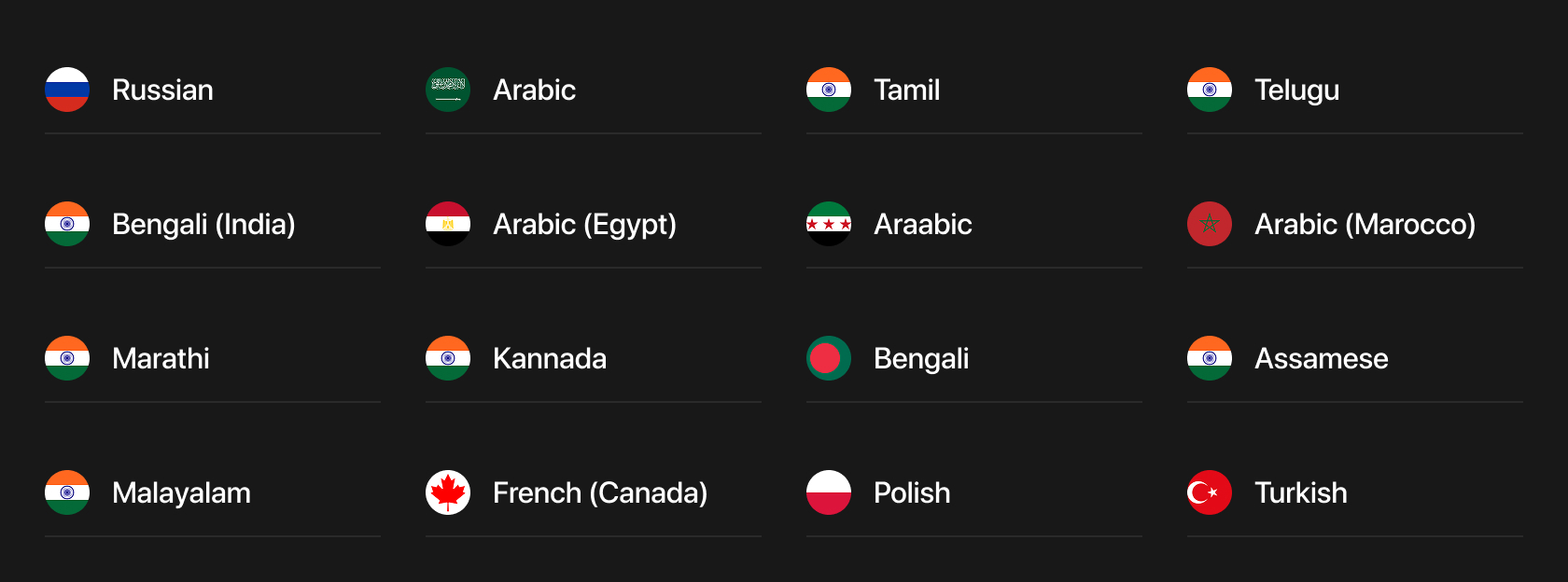
MARS8-Flash, MARS8-Pro, and MARS8-Instruct are being released across multiple languages, collectively covering 99% of the world’s speaking population.
Languages are categorized into Premium and Standard support tiers. Premium support includes languages for which we trained on more than 10,000 hours of data, while Standard support includes languages trained on less than 10,000 hours of data. This distinction reflects data scale, not output quality.
Importantly, every listed language delivers broadcast-grade speech quality and has already supported or continues to support production workloads for large enterprises. We are confident in the performance and reliability of each language offering.
Beyond this, CAMB supports up to 150 languages across the long tail. For additional languages or custom requirements, please contact us to discuss bespoke language support.
Premium Support
Standard Support
Use Cases
Coming soon
Whether you're a media professional or voice AI product developer, this newsletter is your go-to guide to everything in speech and localization tech.
Related Articles

.jpg)





